
SOM team is currently working on the following funded projects. Get in touch if you’re especially interested in any of them (we may even have open positions linked to them).
BOSS: Smart Bots for (Open Source) Software Development – TED Spanish National Project 2023-2024
Software is the underlying infrastructure powering this transformation, and therefore it is critical for the daily activities and future evolution of our society. Most critical software is built as Open Source Software (OSS) or heavily relies on it. As a consequence, it is fair to say that OSS plays a significant role in the European Software economy, with digital businesses built by leveraging Open Source assets. The promise of OSS is better quality, higher reliability, more flexibility and lower cost. However, it suffers from problems such as the tragedy of the commons: everybody uses OSS but very few contribute back. As such, our digital infrastructure stands on shaky grounds, with critical software facing deep sustainability risks. These issues affect companies and public entities and hamper the potential benefits derived from this ongoing digital transition.
This project proposes for a radical shift in the way software is developed and maintained based on a self-guiding swarm of smart software bots to assist projects owners, developers but also occasional contributors and community members in all their software-related tasks. Bots will be trained using a variety of AI techniques, including machine learning models derived from a curated collection of software project data in code hosting platforms like GitHub.
The main goal of the project is Building, One Bot at a Time, a Unified Framework for Sustainable Software Development. More specifically, it aims to transform software development by providing a framework to model, generate, personalize, combine and coordinate smart software bots to help in all phases of software development and maintenance.
This overall objective will be met by way of achieving the following subgoals:
- Building and training models from software historical data.
- Defining languages to build and generate a smart bot infrastructure able to monitor and participate in software development, including the capability to communicate in Natural Language with the project community.
- Enabling effective collaboration and cooperation among all smart bots deployed in the same project.
- Providing guidelines and a library of prepackaged bots to facilitate the immediate adoption of BOSS in all kinds of public and private companies.
The results of this project will have a significant social, scientific and economic impact:
- Social impact: empowering end users and speeding up the digital transition of our society. It will facilitate the participation of all types of users, in the evolution of any software project, which is especially important in the current context of transparency and participatory initiatives in the public administration.
- Scientific impact: transforming software development, as the techniques developed will evolve the way that software projects are built and maintained, maximizing their chances of success.
- Economic impact: providing competitive advantages to national companies and help them to be more agile. Another key long-term impact of the project should be to help other research projects to advance faster by developing a series of artifacts useful to other researcher teams working in this same area.
LOCOSS: Low-code development of smart software – RETOS Spanish National Project 2021-2024
Artificial Intelligence (AI) has achieved remarkable levels of effectiveness in many domains. Examples are the use of chatbots for customer support; medical imaging to help doctors diagnose medical conditions or autonomous vehicles to assist drivers.
AI systems face common challenges in their development: they require a different and specialized skillset; they are hard to specify, test, verify and debug; and are complex to evolve and maintain. Explainability (the ability to justify the decisions made by AI components) and AI ethics (the ability to define and check ethical principles to be respected in such decisions, e.g. the lack of bias) are also of special importance.
Moreover, AI systems are almost always part of a larger software system that embodies them. This combination is usually referred to as AI-enhanced software or simply smart software. Currently, the AI part of smart software is developed separately from the rest. This poses additional challenges: defining the communication between the AI elements and the traditional ones, the end-to-end testing of the global system, their co-evolution, … This complexity can further increase the AI-divide between the tech giants and the rest of the World.
This research project aims to change this situation. Our goal is to simplify the specification, generation, testing, deployment and evolution of any type of smart software thanks to a LOw-COde development platform for Smart Software (LOCOSS).
Low-code application platforms accelerate software delivery by dramatically reducing the amount of hand-coding required. Low-code can be seen as a specific style of Model-Driven Engineering (MDE), a software development paradigm where models rather than source code are the core asset. Models provide an abstract and simplified view of a software system focused on a specific perspective. MDE raises the level of abstraction in software engineering with the benefits of higher quality, technology independence and reduced development costs.
As such, we propose to bring the power of low-code to the development of smart software. This combination has not been deeply studied so far. We believe it can disrupt how smart software is built, lowering the barrier entry to AI development, improving its quality and reducing the overall development effort.
To achieve this ambitious goal, the project will pursue these key research contributions:
- A set of domain-specific languages to facilitate the specification of AI components (e.g. intelligent conversational interfaces, recommender services, …) and their interaction with the non-AI ones.
- A model-based approach for training and optimizing the AI components as part of the smart software specification.
- Explicit high-level formalization of complex non-functional requirements such as security, privacy or fairness, which may otherwise become implicit or scattered in the implementation.
- Code-generation techniques to implement the AI components on top of state-of-the-art AI libraries isolating as much as possible the AI designer from low-level technical details.
- Novel verification, validation and testing techniques to include the quality evaluation of AI components.
The results of this project will have a significant technical, economic and social impact by expanding the number of potential smart software developers and reducing the time-to-market for this type of software, improving the competitiveness of Spanish companies.
AIDOaRT – ECSEL EU
The project idea is focusing on AI-augmented automation supporting modeling, coding, testing, and monitoring as part of a continuous development in Cyber-Physical Systems (CPSs). The growing complexity of CPS poses several challenges throughout all software development and analysis phases, but also during their usage and maintenance.
Many leading companies have started envisaging the automation of tomorrow to be brought about by Artificial Intelligence (AI) tech. While the number of companies that invest significant resources in software development is constantly increasing, the use of AI in the development and design techniques is still immature.
The project targets the development of a model-based framework to support teams during the automated continuous development of CPSs by means of integrated AI-augmented solutions.
The overall AIDOaRT infrastructure will work with existing data sources, including traditional IT monitoring, log events, along with software models and measurements. The infrastructure is intended to operate within the DevOps process combining software development and information technology (IT) operations. Moreover, AI technological innovations have to ensure that systems are designed responsibly and contribute to our trust in their behaviour (i.e., requiring both accountability and explainability).
AIDOaRT aims to impact organizations where continuous deployment and operations management are standard operating procedures. DevOps teams may use the AIDOaRT framework to analyze event streams in real-time and historical data, extract meaningful insights from events for continuous improvement, drive faster deployments and better collaboration, and reduce downtime with proactive detection.
TRANSACT – ECSEL EU
Market trends show advanced usage of safety-critical systems with novel services based on smart data analytics. Customers require continuous updates to applications and services and seek lower cost (Bill-of-Material, BoM) and easy to install solutions (maintenance) for safety-critical cyber-physical systems (CPS).
To respond to these trends, TRANSACT will leverage edge and cloud technologies and establish business partner eco-systems to enhance safety-critical systems in regulated environments.
TRANSACT will transform local safety critical CPS into distributed safety-critical CPS solutions with a heterogeneous architecture composed of components along a device-edge-cloud continuum. The distributed solutions incorporating data and cloud services will simplify the CPS devices, reducing their software footprint, and consequently their BoM and Lower of Cost or Market. Business-wise, system manufacturers thus transform to solution providers. To that end TRANSACT will research distributed reference architectures for safety-critical CPS that rely on edge and cloud computing.
These architectures shall enable seamless mixing of on-device, edge and cloud services while assuring flexible yet safe and secure deployment of new applications, and independent releasing of edge and cloud-based components vs. on-device. Moreover, safety, performance, cybersecurity and privacy of data will be kept on the same level as on-device only safety-critical CPS architectures. By also integrating AI services into distributed CPS, TRANSACT will enable fast development of innovative value-based services and business models leading to faster market introduction in the various multi-billion-euro markets addressed by TRANSACT. Encouraged by ARTEMIS’ 2019 publication on embedded intelligence, TRANSACT will be a crucial enabler for Europe to shift towards a solution-oriented market “so as to still matter in the Embedded & Cyber-Physical Systems field of tomorrow’s world.”
Learning Intelligent Systems – eLearn Center Project 2019-2021
The main objective of this project (LIS) is to develop an adaptive system to be globally applicable at UOC campus to help students to succeed in their learning process. LIS supposed to be widely applicable to all types of courses and independently of the learning resources and contents. It mainly has predictive analytics, predictive progression dashboard, automated feedback and recommendations, and also gamification features designed upon Artificial Intelligence.
Modelia – partnership with CEA List
The goal of the project is the integration of Artificial Intelligence (AI) in software development tools to achieve the cognification of model-driven software engineering tasks and processes.
Software is the infrastructure that powers our digital society. It is everywhere: laptops, phones, watches, cars, electrical household appliances and all kinds of IoT devices around us. And yet, software development is in a permanent state of crisis. Improvements in programming tools, languages and methods have not been able to keep up with the increasing complexity, demands and trust we expect from all running software. This complexity is expected to keep growing in the coming years with the increase in the number of devices, the vast amounts of big data that the software will have to be able to process in real-time and the integration of AI components for all kinds of reasoning and recognition tasks.
We believe that an incremental improvement on current software development tools and techniques is not enough to deal with this situation. Instead, Modelia advocates for a shift in the way software is developed and maintained thanks to the integration of AI techniques in all software development tools and processes. This integration holds the promise of disruptive improvements on the developers’ productivity and the quality of the software developed.
Modelia will combine AI and model-based engineering and aspires to become a leader in the emerging space of Intelligent IDEs that focus on improving the productivity of individual developers by helping them to find and reuse existing code. Modelia will be able to suggest improvements on the models being created based on general knowledge available online, prevent potential errors by continuously monitoring the developer’s actions or automatically detect and suggest the best refactorings.
Past Projects
BODI: Bots for Open Data Interactions – Conversational Interfaces to facilitate the access to public data – Spanish R&D Proof of concept Project 2021-2023
More and more data is published online every day, coming from both the public and private sectors. As an example, the European data portal registers over 400,000 public datasets online.
Most of this data is available via some kind of (semi)structured format (XML, RDF, JSON, etc.) which, in theory, facilitates its consumption and combination. Indeed, the open data movement promises to bring to the fingertips of every citizen all the data they need, whether it is for planning their next trip, or for government oversight.
Unfortunately, this is still far from reality. Our society is opening its data but not building the technology and infrastructure required to empower citizens to access and manipulate it. Only technical people have the skills to consume the heterogeneous data sources while the rest is forced to depend on third-party applications or companies.
This project aims to change this: our goal is to empower all citizens to exploit and benefit from the open data. By removing the technical barrier of access to the data, BODI spreads this economic opportunity and increases its net value. To achieve this ambitious goal, the project proposes to leverage the latest technological advances in conversational interfaces (i.e., chatbots and voicebots) to enable citizens to ask any question they need in natural language. The BODI platform will then process the question and decompose it into a set of technical requests to the API-based open data sources available. At the end of the process, BODI will collect and combine the data to answer the user, also in plain natural language, ensuring a fluent communication.
To achieve this ambitious goal, the project will build on top of the original ODA project and extend it with the following key research contributions:
- Adaptation of the ODA project results on Open Data discovery and composition to the most popular formats in public open data sources at the national and European level.
- Integration of real-time open data sources (e.g., traffic information) to facilitate the application of BODI as part of Smart City initiatives.
- Automatic generation of chatbots tailored to specific combinations of open data sources to provide rich interactive conversations in natural language.
These results will be released as part of the open-source BODI platform, offering for free the technical infrastructure required to have open-data-based conversations. Besides, to maximize the reach and impact of BODI, we will also define a commercialization and exploitation strategy to define a number of offerings we can provide on top of BODI for those companies and institutions that may require customized services.
The results of this project will have a huge impact on our society by finally giving all citizens unrestricted access to the massive amounts of open data available online. This makes any citizen a direct consumer of information, helping her to make more informed decisions in her day-to-day activities. In the public sector, this is a necessary condition, for instance, for the success of initiatives on open governance or direct/liquid democracy, defending the idea of a more active participation of citizens in political aspects. In the private sector, this sudden increase in the number of consumers, i.e., potential clients, will boost the number of businesses built around open data, for instance, making viable the curation and publishing of open data sets focusing on smaller niches.
Open data for All – RETOS Spanish National Project 2017-2020
The goal of the project is to make the promise of open data a reality by giving non-technical users tools they can use to find and compose the information they need.
More and more data is becoming available online every day coming from both the public sector and private sources. As an example, the European data portal registers over 400,000 public datasets online. Most of this data is available via some kind of (semi)structured format (XML, RDF, JSON,…) which, in theory, facilitates its consumption and combination. Indeed, the open data movement promises to bring to the fingertips of every citizen all the data they need, whether it is for planning their next trip or for government oversight.
Unfortunately, this is still far from reality. Our society is opening its data but not building the technology and infrastructure required to enable citizens to access and manipulate it. Only technical people have the skills to consume the heterogeneous data sources while the rest is forced to depend on third-party applications or companies.
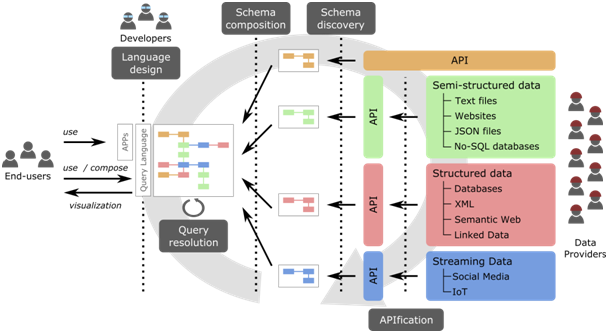
This research project aims to change this. Our goal is to empower all citizens to exploit and benefit from the open data, helping them to become not only consumers but also creators of data that add new value to our society. In this sense, the project will automatically infer a unified global schema of the knowledge available in open data sets and present that schema to the average citizen in a way she can easily browse and query to get the information she needs. This request will be then transparently translated into a combined sequence of accesses to the required data sources to retrieve, visualize and republish it (if desired). When several data sources could be used (e.g. due to an overlap in the exposed data) quality aspects of the source or even monetary costs (some sources may be only partially free) will be taken into account to provide an optimal solution.
To achieve this ambitious goal, the project will pursue the following key research contributions:
- APIfication of data sources: (Web) APIs are becoming the de facto choice for publishing content online. We will unify access to all kinds of data sources via an API interface
- Schema discovery: Most sources won’t have any kind of formal description we could use to precisely understand what information the source provides. A systematic analysis of data samples will help us to infer that schema, enriched with annotations regarding quality aspects (e.g. reliability, availability, etc) to better characterize the data source.
- Schema composition: Individual schemas will be matched and merged to create the global schema representing all available knowledge.
- Citizen languages: Human-computer interaction techniques will be used to build a user-friendly language to express and visualize information requests on this global schema.
- Query resolution: Each request will be translated into an optimal sequence of API calls on the underlying data sources to retrieve the data needed to respond to the request.
The results of this project will have a huge impact on our society by finally giving all citizens unrestricted access to the massive amounts of open data available online. This will also be beneficial to data providers, that could reach a broader audience, and to software companies that will now have a simpler way to build new applications exploiting the links among a diversity of datasets. These benefits will be validated by means of case studies on open data sets provided by the city of Barcelona and the governments of Catalonia and Canarias, implemented on top of an open-source platform released by the project.
The following figure illustrates the proposed approach.
GitHub Organization hosting the tools resulting from this project: https://github.com/opendata-for-all
MegaMart – ECSEL EU – 2017-2020
The goal of the project is to work on Megamodeling at Runtime to build a scalable model-based framework for continuous development and runtime validation of complex systems.
Productivity and quality are two of the major challenges of building, maintaining and evolving large complex and business-critical software systems. In June 2012 Gartner released results of survey on failure of software projects. The survey showed that 28% of large IT projects with a budget exceeding $1M fail. Among the reasons, functionality issues accounted for 22%; late delivery for 28%; and poor quality for 11% of failures. The Standish Group CHAOS report for 2013 states that only 10% of large IT projects delivered on time, on budget and with required features and functions. In the global context, the European industry faces stiff competition. Electronic systems are becoming more and more complex and software intensive, which calls for modern engineering practices to tackle advances in productivity and quality of these now cyber-physical systems. Model-driven Engineering and related technologies promise significant productivity gains, which have been proven valid in several studies. However, these technologies need to be further developed to scale for real-life industrial projects and provide advantages at runtime.
The ultimate objective of enhancing productivity while reducing costs and ensuring quality in development, integration and maintenance can be achieved by the use of techniques that integrate design and runtime aspects within system engineering methods incorporating existing engineering practices. Industrial scale models, which are usually multi-disciplinary, multi-teams, combine several product lines and typically include strong system quality requirements can be exploited at runtime, by advanced tracing and monitoring. Thus, achieving a continuous system engineering cycle between design and runtime, ensuring the quality of the running system and getting valuable feedback from it that can be used to boost the productivity and provide lessons-learnt for future generations of the products.
The major challenge in the Model-Driven Engineering of critical software systems is the integration of design and runtime aspects. The system behaviour at runtime has to be matched with the design in order to fully understand the critical situation, failures in design and deviations from requirements. Many methods and tools exist for tracing the execution and performing measurements of runtime properties. However, these methods do not allow the integration with system models – the most suitable level for system engineers for analysis and decision-making.
Excellence Network on Model-Driven Software Engineering – Spanish National Excellence Networks 2017-2018
The goal of the project is fostering research and technology transfer in MDE in Spain, as well as promoting international research collaborations and projects.
In Software Engineering, Model-Driven Engineering is a paradigm where models replace code as the central artifact of the development process. Working at a high level of abstraction improves productivity and quality, facilitates the portability to new platforms and reduces the maintenance costs, among other benefits. MDE techniques are used in a wide variety of industries, like automotive, telecommunications, banking, embedded systems, etc.
As a starting point, previous scientific networks have fostered an active MDE community and encouraged collaborations, as illustrated by the existence of a theme track in the Spanish “Jornadas de Ingeniería del Software y Bases de Datos” (JISBD). This excellence network aims to consolidate this community by uniting the research groups and companies working in the MDE field and exploring the major scientific and technical challenges in the state -of-the-art: scalability, usability, construction and integration of tools, new application domains, etc. The network’s team includes ten of the most active Spanish research groups within the MDE field: SOM Research Lab (Univ. Oberta de Catalunya), ATENEA (Univ. de Málaga), Alarcos (Univ. de Castilla-La Mancha), TaTAmI (Univ. Politècnica de València), Quercus (Univ. de Extremadura), Informática Aplicada TIC (Univ. de Almería), miso (Univ. Autónoma de Madrid), Information Modeling and Processing (Univ. Politècnica de Catalunya), Modelum (Univ. de Murcia) and Kybele (Univ. Rey Juan Carlos).
This network has two main priorities. First, stimulating the scientific excellence of the MDE community, e.g. increasing international collaborations and projects. And second, consolidating the adoption of MDE technologies among industries, through initiatives such as industrial doctorates or the participation in industrial consortiums and technology platforms.
The planned actions include biannual meetings, short visits among researchers in the network, invitations to international researchers, a summer school for students and young researchers in MDE and a portal focused on promoting collaborations with companies. To encourage internationalization and maximize their impact, some of these actions will be linked to international scientific events organized by the members of the network.
Gamification for Modeling Tools – CEA – 2017
The goal of the application of the use of game design elements in non-game contexts to engage more external developers and end-users on Papyrus
Model Driven Engineering (MDE) has been widely recognized as a major advance in the design and development of complex systems that must respond to rapidly evolving target platforms and increasing functional complexity. With the emergence of large collaborative environments such as Eclipse projects, it becomes possible to capitalize on technologies to provide efficient tooling to support MDE activities.
Papyrus, a stable and powerful Open Source UML/SysML tool suite, goes in this direction. It helps MDE designers in the maintenance and evolution of the system by providing tooling support close to process practices and concepts used in the application domain. Furthermore, being based on Eclipse, it benefits from a world-wide visibility, reflected by the activity in the Eclipse forum and social media (i.e., YouTube, Twitter).
Despite such good conditions to become a very popular platform for both industrial and research activities around MDE, Papyrus is currently not able to exploit them to build a constant, large and self-motivated community of external developers and end-users that really contribute to the advancement of the platform.
Following the success obtained on several platforms (Foursquare , Jenkins , Jira , Visual Studio , etc.), the objective of this project is to apply the use of game design elements in non-game contexts (“Gamification”) to engage more external developers and end-users on Papyrus. Depending on the level and type of activity performed by end-users and developers, we could offer rewards that span from digital badges and physical goodies to trips and even maybe internship or job proposals.
Gamification for end-users
When it comes to using Papyrus for education purposes or for basic end-users, the tool might appear too detailed and powerful. A recent initiative, Papyrus for Education , tackles this issue and provides a set of mechanisms to adapt the tool to the user needs and expertise. Following such an initiative and to make the tool even more attractive for newbies, the objective is to build a set of modeling-related games (based on quizzes and quick exercises) on top of Papyrus that can be used to self-assess the modeling knowledge of the user and its familiarity with the tool and the UML/SysML languages in a playful way. We will also explore how these tests could be personalized based on the monitoring of the user activity on the platform as a way to detect what errors s/he is doing, what parts of the platform s/he is not exploring.
Gamification for developers
Monitoring and analyzing the activity of the community around a software project is paramount to assess its health and resilience. This requires gathering data of the community activity in different online sites and platforms. In particular, for this project, we will harvest data from the Papyrus tools (e.g., Papyrus Git repository, GitHub, Bugzilla and Eclipse forums). Then we will define several metrics on this data to determine the activity levels of each individual and his possible rewards based on the game levels defined.
Study and Definition of a governance model for Decidim
The goal of this project was to study the development process followed in Decidim, a plaform for participatory democracy which enables the creation of citizen participation portals , and to make explicit its governance model
The development of Open Source Software (OSS) usually follows a method that harnesses the power of distributed peer review and transparency. Indeed, OSS is typically developed in a collaborative manner via online hosting platforms like GitHub. However, in practice, many OSS projects are not as open as they should.
The Decidim project is a platform aimed at creating participatory portals. The platform defines a social contract for democratic guarantees and open collaboration for the community around the project. Furthermore, the development of the Decidim project is overseen by Metadecidim,
another participatory portal devoted to allow anyone to contribute and discuss new features (or improvements) for the platform.
Governance rules help to prioritize and manage tasks, and contribute to the long-term sustainability of the project by clarifying how developers (and end-users) should collaborate. Despite their importance, these rules are usually implicit or scattered in the project documentation/tools. In this project we explore the explicit definition and enforcement of governance rules for the Decidim project.